
ML- Ops: Drift Detection in Data & Iterative model training using python's Multi-flow package
- Mr. Data Bugger
- Aug 18, 2021
- 2 min read
Updated: Sep 21, 2021
we develop a ML model and deploy but who takes care of model monitoring and re-training. Unless we do it, ur project is no more than a college assignment.
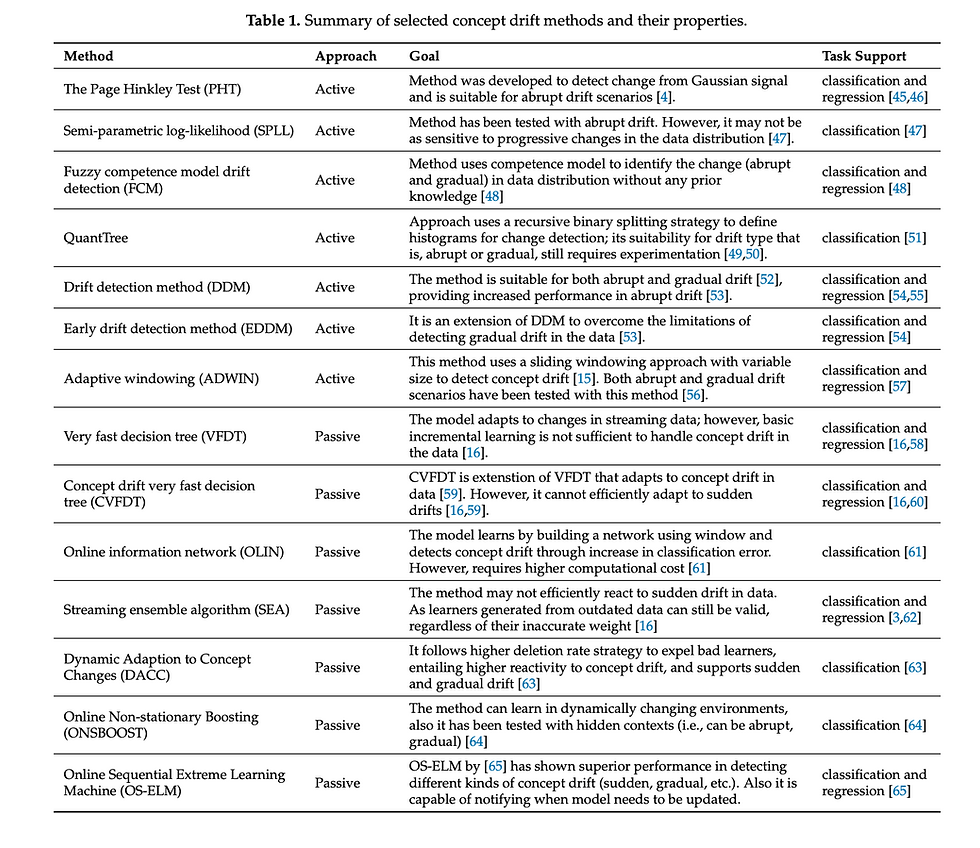
There are many techniques to incorporate concept drift/model drift.
Active approach- where retraining happens only when drift is detected in data. Passive approach- when continuous retraining happens assuming drift is always present in data. many approaches also detect warning zone along with 'if there is drift or not.'
Drift Detection Method based on Hoeffding’s bounds with moving weighted average-test
# create a function to generate data
def gen_data(mean, sd ,sample_size, number_cols):
'''
sd= standard deviation
number_cols= number of. cols in output data
'''
df= np.random.normal(3, 2.5, size=(sample_size, number_cols))
return(df)# creating n distributions
df= np.random.normal(3, 0, size=(30, 3))
for i in range(30):
df2= np.random.normal(3, i+1, size=(30, 3))
df= np.vstack([df, df2])# Plotting data
import matplotlib.pyplot as plt
plt.plot(df[:,0])
plt.show() # plotting for 1 col only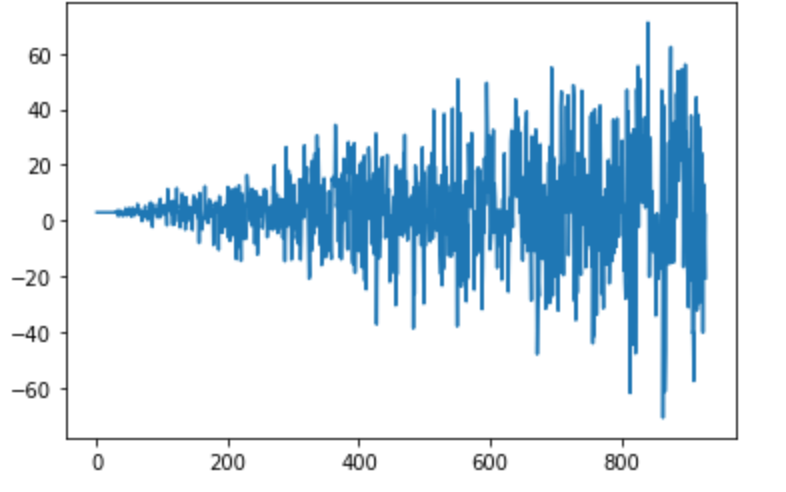
# test by Hoeffding bound method of drify detection
from skmultiflow.drift_detection.hddm_w import HDDM_W
hddm_w = HDDM_W()
for i in range(len(df)):
hddm_w.add_element(df[i,0])
if hddm_w.detected_warning_zone():
print('Warning zone has been detected in data: ' + str(df[i]) + ' - of index: ' + str(i))
if hddm_w.detected_change():
print('Change has been detected in data: ' + str(df[i]) + ' - of index: ' + str(i))# output of drift detection-

fitting Adaptive Random Forest for forecasting.
# Imports
from skmultiflow.data import RegressionGenerator
from skmultiflow.meta import AdaptiveRandomForestRegressor
import numpy as np# fitting the model for 200 data points
# Setup the Adaptive Random Forest regressor
arf_reg = AdaptiveRandomForestRegressor(random_state=123456)
# Run test-then-train loop for max_samples and while there is data
y_pred=[]
for i in range(200):
X=df[i,0:2].reshape(1,2)
y=df[i,2].reshape(1)
y_pred.append(arf_reg.predict(X)[0])
arf_reg.partial_fit(X, y)# checking the model performance
y_true = list(df[:200,2].reshape(200,))
# Display results
print('Adaptive Random Forest regressor example')
print('Mean absolute error: {}'.format(np.mean(np.abs(np.array(y_true) - np.array(y_pred)))))
print('Mean absolute error: {}'.format(np.mean(np.abs(y_true - y_pred))))
# Visualise the performance
y_true= np.array(y_true).reshape(200,)
data_for_plot= np.abs(y_true - y_pred)
plt.plot(data_for_plot)
plt.title('performace on continious model retraining')
plt.ylabel('error-prediction')
plt.show()
references-
file:///Users/apple/Downloads/smartcities-04-00021-v3.pdf
Comments